
「生成AIはなぜ自然な文章を書けるのか?」「ChatGPTやClaudeの中身はどうなっているのか?」
生成AIを業務に導入する企業が増える中、仕組みを理解していないために適切なツール選定や運用設計ができないケースが多く見受けられます。技術の詳細を知る必要はありませんが、基本的な仕組みを理解することで、より効果的な活用が可能になります。
本記事では、生成AIの仕組みをLLM(大規模言語モデル)→Transformer→RAG(検索拡張生成)の3段階でわかりやすく解説します。AIエージェントとは?で紹介しているエージェント技術との関係も含めて説明します。
生成AIの仕組み — 3つの技術レイヤー
生成AIの仕組みは、大きく3つの技術レイヤーで構成されています。
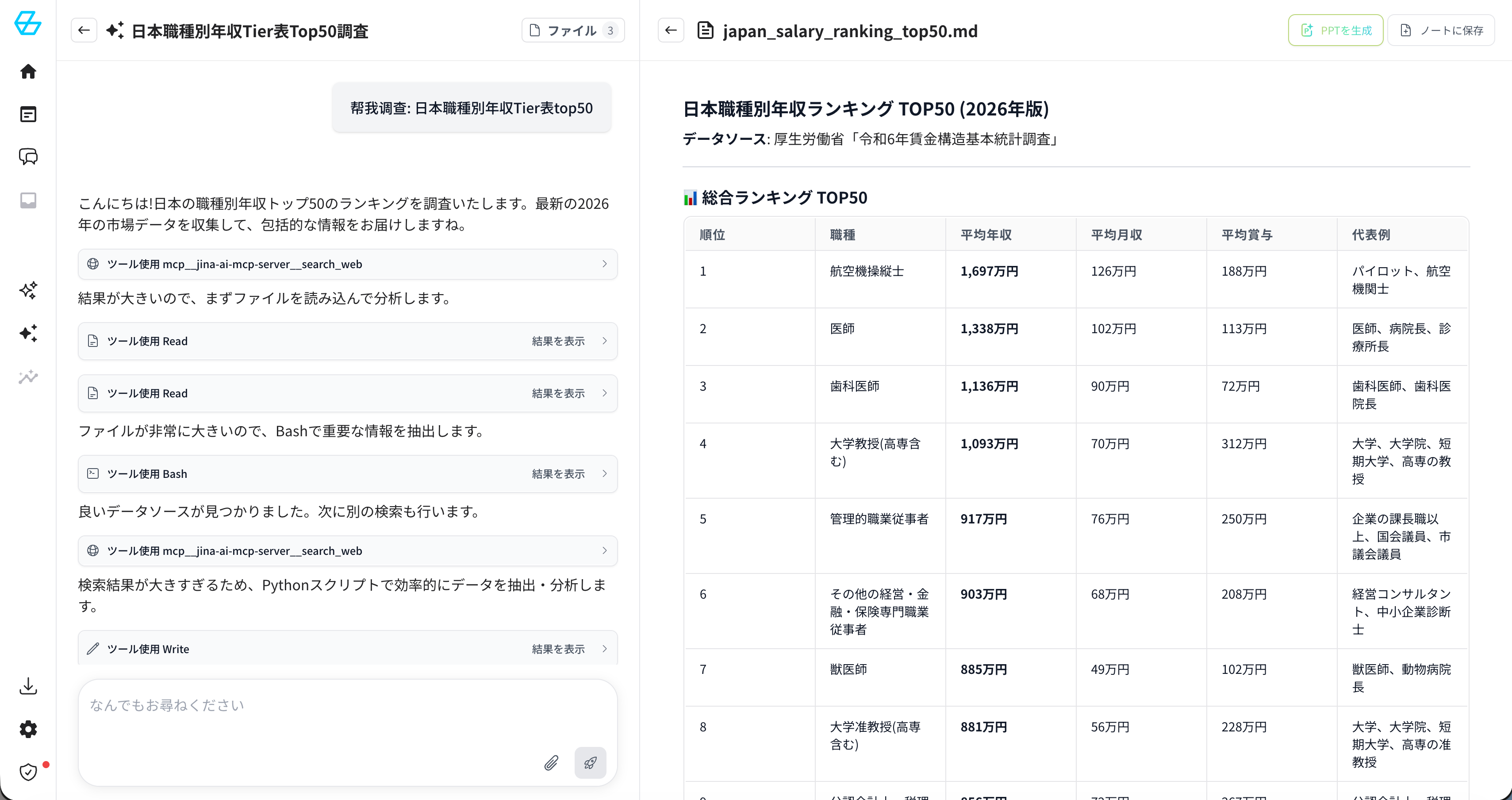
| レイヤー | 技術 | 役割 | 例 |
|---|---|---|---|
| 基盤モデル | LLM(大規模言語モデル) | 言語の理解と生成 | GPT-4、Claude、Gemini |
| アーキテクチャ | Transformer | 文脈を考慮した処理 | Attention機構 |
| 業務応用 | RAG(検索拡張生成) | 外部データとの連携 | GBase Knowledge |
レイヤー1:LLM(大規模言語モデル)とは
LLM(Large Language Model)は、生成AIの中核技術です。インターネット上の膨大なテキストデータを学習し、「次に来る言葉」を予測することで文章を生成します。
LLMの学習プロセス
| 段階 | 内容 | 目的 |
|---|---|---|
| 事前学習 | 大量のテキストデータから言語パターンを学習 | 一般的な言語知識の獲得 |
| ファインチューニング | 特定のタスクに特化した追加学習 | 精度の向上 |
| RLHF | 人間のフィードバックによる強化学習 | 安全性と有用性の向上 |
LLMのパラメータ数(モデルの大きさ)が大きいほど、より自然で正確な文章を生成できます。GPT-4は推定1兆以上のパラメータを持つとされています。
レイヤー2:Transformerアーキテクチャ
現代の生成AIの多くは、Transformerと呼ばれるアーキテクチャで構築されています。2017年にGoogleの研究者が発表した「Attention Is All You Need」という論文で提案された技術です。
Transformerの仕組み(簡略版)
| 要素 | 役割 | たとえ |
|---|---|---|
| Self-Attention | 文中の各単語が他の単語との関係性を計算 | 「彼は東京に行った。そこで…」→「そこ」が「東京」を参照していると理解 |
| エンコーダ | 入力テキストの意味を数値に変換 | 日本語の文章を「意味ベクトル」に変換 |
| デコーダ | 数値から新しいテキストを生成 | 「意味ベクトル」から回答文を生成 |
このAttention機構により、生成AIは長い文脈を考慮して、前後の関係性を踏まえた自然な文章を生成できます。
レイヤー3:RAG(検索拡張生成)
RAG(Retrieval-Augmented Generation)は、生成AIを企業の実務で使えるようにするための重要な技術です。
RAGが解決する課題
LLM単体では以下の問題があります。
| 課題 | 説明 | RAGによる解決 |
|---|---|---|
| ハルシネーション | 事実と異なる情報を生成する | 実データを参照して回答するため、正確性が向上 |
| 知識の鮮度 | 学習データが古く、最新情報を知らない | リアルタイムで外部データを検索して回答 |
| 社内知識の欠如 | 自社固有の情報を知らない | 社内ナレッジベースを参照して回答 |
RAGの処理フロー
- ユーザーが質問を入力
- AIが社内ナレッジベースから関連情報を検索(Retrieval)
- 検索結果を文脈に追加(Augmented)
- LLMが検索結果をもとに回答を生成(Generation)
ワークフローに生成AIを導入する完全ガイドで解説しているように、GBase KnowledgeはこのRAGの仕組みをノーコードで構築できるプラットフォームです。
生成AIの仕組みを理解することで何が変わるか
仕組みを理解することで、以下の3つの判断が適切にできるようになります。
判断1:ツール選定の精度が上がる
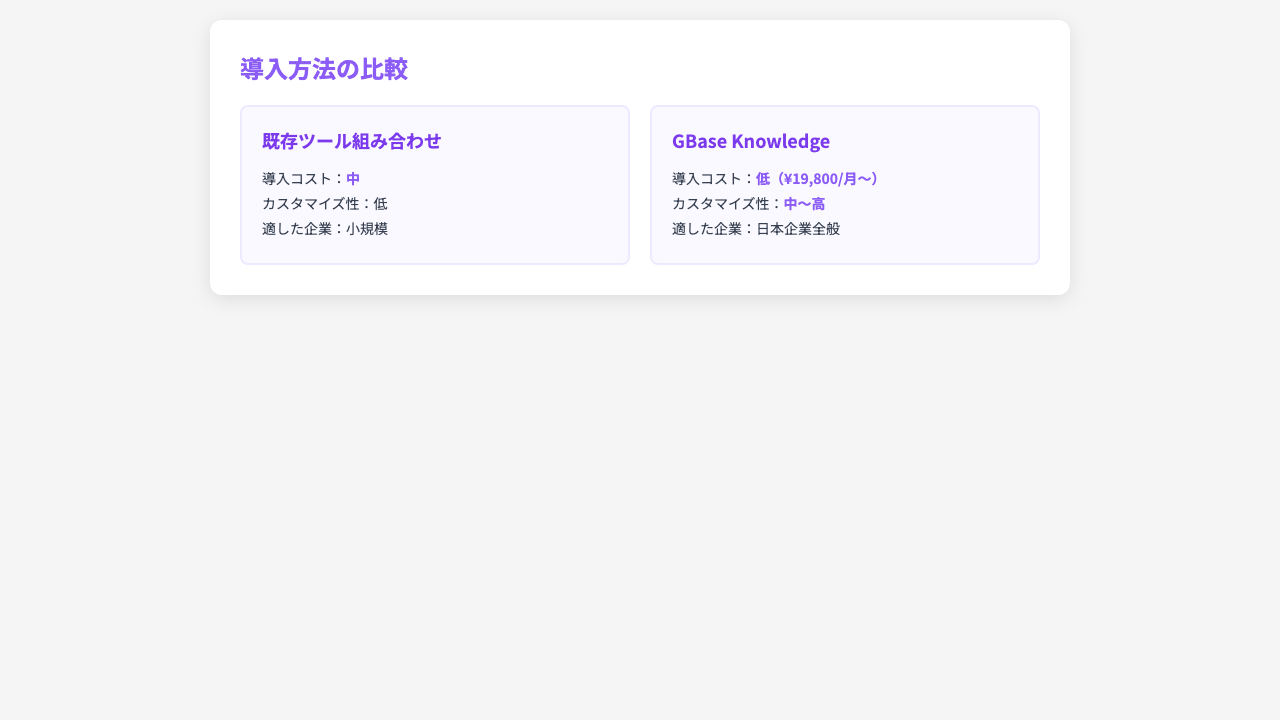
LLM単体のツール(ChatGPT個人利用)と、RAG搭載のプラットフォーム(GBase Knowledge)では、業務での効果が大きく異なります。仕組みを知ることで、自社に必要な技術レベルを正しく判断できます。
判断2:プロンプト設計が上手くなる
AIが「次の単語を予測する」仕組みだと理解すれば、具体的で詳細なプロンプトが重要な理由が分かります。曖昧な指示では予測の方向性が定まらず、期待外れの出力になるのは当然です。
判断3:AIの限界を正しく理解できる
ハルシネーションが起きる理由(学習データに基づく確率的な予測であるため)を理解すれば、AIの出力を盲信せず、適切な人間によるチェック体制を構築できます。

GBase KnowledgeはRAGの仕組みをノーコードで実現できるプラットフォームです
GBase Knowledgeの仕組み — RAGを業務に活かす
GBase Knowledgeは、RAGの仕組みをベースに、社内データの管理からAIエージェントの構築、ワークフローの自動化までを一元化したプラットフォームです。
STEP 1:ナレッジベースの構築(データの準備)
社内ドキュメント(PDF・Word・Excel・PowerPoint)をアップロードすると、GBase Knowledgeが自動的にテキストを抽出し、ベクトル化(数値に変換)して検索可能な状態にします。

STEP 2:AIエージェントの設定(RAGの活用)
アップロードしたデータをもとに、AIエージェントを作成します。ユーザーの質問に対し、ナレッジベースから関連情報を検索し、その情報をもとにLLMが回答を生成します。エージェント型AIとは?の設計原則に基づき、用途別にエージェントを最適化できます。
STEP 3:ワークフローの構築(業務への統合)
RAGの仕組みをワークフローに組み込むことで、定型業務を自動化します。AI ワークフローとは?業務効率を最大化する導入ガイドも参考に、段階的に自動化の範囲を拡大していくのがおすすめです。
よくある質問(FAQ)
Q1. 生成AIの仕組みを理解していなくても使えますか?
A. はい、使えます。GBase Knowledgeのようなノーコードプラットフォームであれば、技術的な知識がなくても利用可能です。ただし、仕組みの基本を理解しておくと、より効果的な活用ができるようになります。
Q2. LLMとGPTの違いは何ですか?
A. LLM(大規模言語モデル)は技術カテゴリの名称で、GPTはOpenAIが開発したLLMのシリーズ名です。GPTの他にも、Claudeの基盤モデルやGeminiの基盤モデルなど、様々なLLMが存在します。
Q3. RAGとファインチューニングの違いは?
A. RAGは外部データを検索して参照する仕組みで、モデル自体は変更しません。ファインチューニングはモデル自体を追加学習で変更する手法です。企業利用では、コストが低く柔軟性の高いRAGが主流です。GBase KnowledgeはRAG方式を採用しています。
Q4. 生成AIのハルシネーションは防げますか?
A. 完全に防ぐことは困難ですが、RAGの仕組みを使えば大幅に軽減できます。社内データを参照して回答を生成するため、根拠のない情報を生成するリスクが低下します。AIが変える営業資料作成で紹介しているように、出典情報を表示する機能も有効です。
Q5. 生成AIの仕組みは今後どう進化しますか?
A. マルチモーダル化(テキスト・画像・音声の統合)、推論能力の向上、エージェント化(自律的なタスク実行)が進んでいます。SOPとは?で解説している業務標準化と合わせて、AIの活用範囲は今後さらに拡大していくでしょう。
Q6. 自社データを使ったRAGの構築は難しいですか?
A. GBase Knowledgeであれば、プログラミング不要でRAGを構築できます。ドキュメントをアップロードし、AIエージェントを設定するだけで、自社データに基づいた回答が得られます。パワポ生成AIでレポート作成が10分にのような活用事例も参考にしてください。
まとめ
生成AIの仕組みは、LLM(言語の理解と生成)→ Transformer(文脈を考慮した処理)→ RAG(外部データとの連携)の3つのレイヤーで構成されています。
企業が生成AIを業務で効果的に活用するためには、LLM単体ではなくRAGの仕組みを活用して社内データと連携させることが不可欠です。GBase Knowledgeを使えば、このRAGの仕組みをノーコードで即日構築できます。
本記事のポイント
- 生成AIの中核はLLM(大規模言語モデル)とTransformerアーキテクチャ
- 企業活用にはRAG(検索拡張生成)が不可欠
- RAGにより、ハルシネーション軽減+社内データ活用が実現
- GBase KnowledgeはRAGをノーコードで構築可能

